



机器学习对抗性攻击报告 |
| 来源:聚铭网络 发布时间:2017-01-09 浏览次数: |
信息来源:FreeBuf
从12月29日起,神秘的账号Master在弈城、野狐等围棋对战平台上轮番挑战各大围棋高手,并取得了不可思议的多连胜。1月4日,聂卫平、常昊、周睿羊等高手接连输给Master,到目前截止它已获得60连胜。Master在与古力的对决之前终于揭晓了自己的身份,果然就是去年大出风头的AlphaGo(升级版),而对阵古力,也提前声明了会是最后一战。 我们不妨将Master的60连胜视为人工智能与人类交锋的信号和警报,在人工智能时代人类如何完成自身的“刷新升级”值得每个人思考。同时其带来的安全问题也急需安全专家去突破。
随着人工智能和机器学习技术在互联网的各个领域的广泛应用,其受攻击的可能性,以及其是否具备强抗打击能力一直是安全界一直关注的。之前关于机器学习模型攻击的探讨常常局限于对训练数据的污染。由于其模型经常趋向于封闭式的部署,该手段在真实的情况中并不实际可行。在GeekPwn2016硅谷分会场上,来自北美工业界和学术界的顶尖安全专家们针对当前流行的图形对象识别、语音识别的场景,为大家揭示了如何通过构造对抗性攻击数据,要么让其与源数据的差别细微到人类无法通过感官辨识到,要么该差别对人类感知没有本质变化,而机器学习模型可以接受并做出错误的分类决定,并且同时做了攻击演示。以下将详细介绍专家们的攻击手段。 1. 攻击图像语音识别系统目前人工智能和机器学习技术被广泛应用在人机交互,推荐系统,安全防护等各个领域。具体场景包括语音,图像识别,信用评估,防止欺诈,过滤恶意邮件,抵抗恶意代码攻击,网络攻击等等。攻击者也试图通过各种手段绕过,或直接对机器学习模型进行攻击达到对抗目的。特别是在人机交互这一环节,随着语音、图像作为新兴的人机输入手段,其便捷和实用性被大众所欢迎。同时随着移动设备的普及,以及移动设备对这些新兴的输入手段的集成,使得这项技术被大多数人所亲身体验。而语音、图像的识别的准确性对机器理解并执行用户指令的有效性至关重要。与此同时,这一环节也是最容易被攻击者利用,通过对数据源的细微修改,达到用户感知不到,而机器接受了该数据后做出错误的后续操作的目的。并会导致计算设备被入侵,错误命令被执行,以及执行后的连锁反应造成的严重后果。本文基于这个特定的场景,首先简单介绍下白盒黑盒攻击模型,然后结合专家们的研究成果,进一步介绍攻击场景,对抗数据构造攻击手段,以及攻击效果。 1.1 攻击模型和其他攻击不同,对抗性攻击主要发生在构造对抗性数据的时候,之后该对抗性数据就如正常数据一样输入机器学习模型并得到欺骗的识别结果。在构造对抗性数据的过程中,无论是图像识别系统还是语音识别系统,根据攻击者掌握机器学习模型信息的多少,可以分为如下两种情况: · 白盒攻击 攻击者能够获知机器学习所使用的算法,以及算法所使用的参数。攻击者在产生对抗性攻击数据的过程中能够与机器学习的系统有所交互。 · 黑盒攻击 攻击者并不知道机器学习所使用的算法和参数,但攻击者仍能与机器学习的系统有所交互,比如可以通过传入任意输入观察输出,判断输出。 2. GeekPwn现场机器学习对抗性攻击2.1 Physical Adversarial Examples在GeekPwn2016硅谷分会场上,来自OpenAI的Ian Goodfellow和谷歌大脑的Alexey Kurakin分享了“对抗性图像”在现实物理世界欺骗机器学习的效果。值得一提的是,Ian Goodfellow正是生成式对抗神经网络模型的发明者。 首先先简单介绍一下对抗性图像攻击。对抗性图像攻击是攻击者构造一张对抗性图像,使人眼和图像识别机器识别的类型不同。比如攻击者可以针对使用图像识别的无人车,构造出一个图片,在人眼看来是一个stopsign,但是在汽车看来是一个限速60的标志。
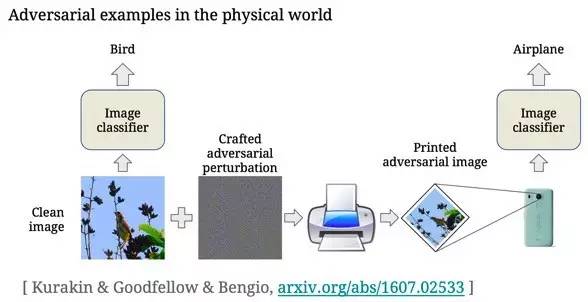
图1 攻击图像识别场景 在会上,Ian和Alexey指出过去的对抗性图像工作都基于如下的攻击模型,即攻击者可以直接向机器学习模型输入数据,从而保证攻击者可以随心所欲地对任意粒度的图片进行修改,而不需要考虑灯光,图片角度,以及设备在读取图片时对对抗性图像攻击效果产生变化。因此,他们尝试了对抗性图片在真实物理世界的表现效果,即对抗性图片在传入机器学习模型之前,还经过了打印、外部环境、摄像头处理等一系列不可控转变。相对于直接给计算机传送一张无损的图片文件,该攻击更具有现实意义。 在如何构造对抗性攻击图片上,他们使用了非定向类攻击中的FGS和FGS迭代方法,和定向类的FGS迭代方法 [1]。其中,非定向类攻击是指攻击者只追求对抗图像和原图像不同,而不在意识别的结果是什么。定向类攻击则是指攻击者在构造图像时已经预定目标机器学习模型识别的结果。 在定向类攻击中,作者首先根据条件概率找出给定源图像,最不可能(least-likely)被识别的类型y值,表示为(该种类通常和原种类完全不同)。然后采用定向类攻击方法中的FGS迭代方法,产生对抗性图片。其中非定向类攻击方法在类型种类比较少并且类型种类差距较大的数据库里,比较有效。但是一旦类型之间比较相关,该攻击图像有极大的可能只会在同一个大类中偏移。这时候定向类攻击方法就会有效很多。
图2 对抗性图像在现实物理世界欺骗机器学习过程 为了验证结果,作者采用白盒攻击模型。其中,作者使用谷歌Inception v3作为目标图像识别模型,并选取ImageNet中的50,000个验证图像针对Inception v3构造出相对应的对抗性图像。在实验中,他们将所有的对抗性图片和原始图片都打印出来,并手动用一个Nexus 5智能手机进行拍照,然后将手机里的图像输入Inception v3模型进行识别。现场结果表明,87%的对抗性图像在经过外界环境转化后仍能成功欺骗机器,从而证明了物理对抗性例子在真实世界的可能性。 在他们的论文中,作者还测试了物理世界造成的图像转化对使用不同方法构造的对抗性图片的毁坏程度。有意思的结论是迭代方法受图像转化的影响更大。这是因为迭代方法对原图像使用了更微妙的调整,而这些调整在外界图像转化过程中更容易被毁坏。作者还分别测试了亮度、对比度、高斯模糊转化、高斯噪音转化和JPEG编码转化量度,对各个对抗性图像方法的毁坏程度。具体实验结果请参见他们的论文 [1]。 2.2 Exploring New Attack Space on Adversarial Deep Learning来自UC Berkeley大学的Dawn Song教授和刘畅博士介绍了对抗式深度学习在除了其他领域的攻击和防御。其中Dawn Song教授是Taint Analysis理论的主要贡献者之一,还是美国“麦克阿瑟天才奖”获得者。在现场,专家们首先拓展了对抗性深度学习在图像识别检测上的应用,然后还提出构造对抗性图片的优化方法-ensemble黑盒攻击算法[6]。 在图像识别物体检测中,如图3左图所示,深度学习可以用来检测图像中不同的物体以及他们之间的关系并自动生成说明(Caption) [2]。在这种场景下,对抗性图像攻击同样可以欺骗机器学习模型,并给出异常的说明,如图3右图所示。对抗性图像构建的基本思路是给定Caption的前缀后,尽量误导之后的判断。
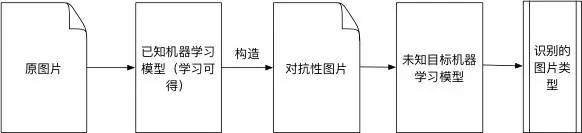
图3 对抗性图片在图像识别检测中的应用 同时,专家们还研究了对抗性图像攻击在黑盒分类模型中的表现,并且提出了优化算法-ensemble黑盒攻击算法。在通常情况下,攻击者并不知道目标模型使用了什么算法已经相关的参数。这时候攻击者只能使用黑盒模型攻击。过程如下所示:
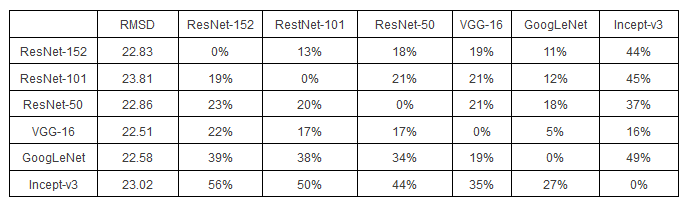
图4 对抗性图像黑盒攻击流程 这一攻击基于对抗性图像的欺骗传递性,即针对机器学习模型A构造的对抗性图像,也会有很大的比例能欺骗机器学习模型B。表1展示了使用单网络优化方法时,针对不同元模型构造的非定向对抗性图像,被不同目标模型识别的成功率。每一个格子(i,j)代表针对算法模型i产生的对抗图片,在其他算法模型j上验证的结果,百分比表示所有对抗性图片中被识别成原图片类型的比例。可以看出,当同一个图像识别系统被用来构造和验证对抗性图像时(白盒攻击模型),百分比为0。这说明在白盒攻击模型中,构建对抗性图像的效果非常好,全部不能正确识别。当验证模型和构造模型并不一致时,大部分对抗性图像的百分比也在10%-40%之间浮动,该结果有效证明了对抗数据在不同算法之间有一定的传递性。
表1 针对不同源机器学习模型构造的非定向对抗性攻击方法(单网络优化方法)在目标模型的攻击效果。其中,ResNet-50, ResNet-101, ResNet-152,GoogLeNet,Incept-v3和VGG-16是当下流行的深度神经网络图像识别系统。 然而,作者还使用了同样的实验方法测试了定向性对抗性攻击在目标模型的效果。结果表明定向类标记的传递性差了很多,只有小于等于4%的对抗性图像在源、目标机器学习模型中都识别出相同的定向标记。 基于此,作者提出了ensemble方法。它是以多个深度神经网络模型为基础构造对抗图片,即将图4中单个已知机器学习模型替换成多个不同的已知机器学习模型,并共同产生一个对抗性图像。 在实验设计中,作者对5个不同的深度神经网络模型一一实施了黑盒子攻击。在对每一个模型攻击的时候,作者假设已知其余的4个模型,并用集合的方式作白盒子对抗图形的构造。同样的,作者分别使用基于优化的攻击手段,和基于Fast Gradient的手段构造对抗性图片。构造图片依然使用的是Adam优化器。在算法经过100次的迭代对权重向量的更新,loss function得以汇聚。作者发现有许多攻击者预先设定的标记也得到了传递。详细结果参见表2。格子(i,j)代表用除了模型i之外的4个其他算法生成的对抗图片,用模型j来验证得到的定向标记的准确值。可以看出,当目标模型包含在已知模型集合中,定向类标记的传递性都在60%以上。即使目标模型不在已知模型集合中,定向标记的准确值也在30%以上。
表2 针对不同源机器学习模型构造的定向对抗性攻击方法(ensemble方法)在目标模型的攻击效果。 作者同样使用了ensemble算法进行非定向攻击。攻击结果如表3所示。可以看出和表1相比,ensemble算法的欺骗性大幅度提升。
表3 针对不同源机器学习模型构造的非定向对抗性攻击方法(ensemble方法)在目标模型的攻击效果。 2.3 Hidden Voice Commands
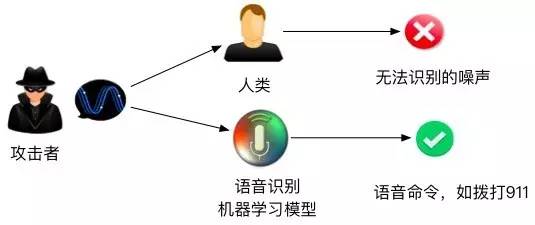
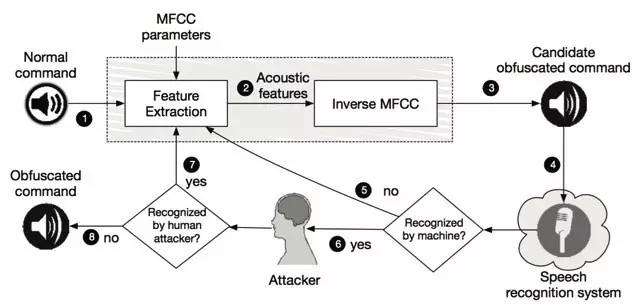
图5 攻击语音识别场景 来自美国Georgetown University的Tavish Vaidya博士分享了隐匿的语音命令这一工作。 对抗性语音攻击则是攻击者构造一段语音,使人耳和语音识别机器识别的类型不同。语音攻击和图像攻击最大的不同在于,它希望保证对抗性语音和原语音差距越远越好,而不是保持对抗性语音和原语音的相似性。该团队依据现实情况,分别提出了黑盒攻击和白盒攻击两种类型。在他们的实验中,扬声器发出一段人类无法辨认的噪音,却能够在三星Galaxy S4以及iPhone 6上面被正确识别为相对应的语音命令,达到让手机切换飞行模式、拨打911等行为 [3]。 黑盒攻击(语音识别): 在黑盒攻击模型中,攻击者并不知道机器学习的算法,攻击者唯一的知识是该机器使用了MFC算法。MFC算法是将音频从高维度转化到低纬度的一个变换,从而过滤掉一些噪声,同时保证机器学习能够操作这些输入。但是从高维到低维的转化过程中,不可避免地会丢失一些信息。相对应的,从低维到高维的转化,也会多添加一些噪声。黑盒攻击的原理正是攻击者通过迭代,不断调整MFCC的参数并对声音进行MFCC变换和逆变换,过滤掉那些机器不需要,而人类所必须的信息,从而构造出一段混淆的语音。因为MFC算法被大量用于语音识别这个场景,所以该攻击模型仍保证了很强的通用性。该具体步骤如图4所示,感兴趣的读者可以参见他们的论文 [3].
图6 对抗性语音黑盒攻击模型[3] 在实验中,作者发现使用的语音识别系统只能识别3.5米之内的语音命令。在扬声器和手机的距离控制在3米的情况下,表4统计了人类和机器对不同命令的识别的比例。平均情况下,85%正常语音命令能被语音识别。在他们的混淆版本中,仍有60%的语音命令能被正常识别。在人类识别类别中,作者使用Amazon Mechanical Turk服务,通过crowd sourcing的形式让检查员猜测语音的内容。在这种情况下不同的命令混淆的效果也不尽相同。对于”OK Google”和”Turn on airplane mode”命令,低于25%的混淆命令能够被人类正确识别。其中,94%的”Call 911”混淆版本被人类正常识别比较异常。作者分析了两个主要原因。1是该命令太过熟悉。2是测试员可多次重复播放语音,从而增加了猜测成功的概率。
表4 对抗性语音黑盒攻击结果。[3] 白盒攻击(语音识别): 在白盒子攻击中,该团队对抗的目标机器学习算法是开源的CMU Sphinx speech recognition system [4]。在整个系统中,CMU Sphinx首先将整段语音切分成一系列重叠的帧(frame), 然后对各帧使用Mel-Frequency Cepstrum (MFC)转换,将音频输入减少到更小的一个维度空间,即图7中的特征提取。然后,CMU Sphinx使用了Gaussian Mixture Model(GMM)来计算特定音频到特定音素(phoneme)的一个概率。最后通过Hidden Markov Model(HMM),Sphinx可以使用这些音素(phoneme)的概率转化为最有可能的文字。这里GMM和HMM都属于图7中的机器学习算法。
图7 CMU Sphinx speech recognition system模型[4] 在Tavish的白盒攻击模型中,他分别提出了两个方法:1.simple approach 2. Improved attack. 第一个方法和黑盒方法的不同点在于,它已知了MFCC的各参数,从而可以使用梯度下降更有针对性地只保留对机器识别关键的一些关键值。在整个梯度下降的过程中,input frame不断地逼近机器识别的目标y,同时人类识别所需的一些多余信息就被不可避免地被剔除了。 第二类白盒攻击的基本原理是依据机器和人对音高低起伏变化(音素)的敏感性不同,通过减少每个音素对应的帧(frame)的个数,让这段声音只能被机器识别,而人类只能听到一段扁平混乱的噪音。这些特征值再经过MFCC逆变换,最终成为一段音频,传到人们耳中。具体的方法和语音相关的知识更密切一下,有兴趣的读者可以看他们的论文了解具体的方法。表5展示了他们的攻击效果。
表5 对抗性语音白盒攻击效果。[3] 2.4 对抗性数据的防护虽然对抗性数据攻击的发现很巧妙,但是在当前图像语音识别应用的场合上,有效的防御并不困难。主要有以下几类: 1. 增加人类交互认证,例如机器可以简单地发出一声警报、或请求输入音频验证码等方式。 2. 增强对抗性数据作为机器学习模型的输入的难度。例如语音识别系统可以使用声纹识别、音频滤波器等方式过滤掉大部分恶意语音。 3. 从机器学习模型本身训练其辨别良性、恶意数据的能力。这时候,这些已知的对抗性数据就提供了珍贵的训练数据。 4. 宾州州立大学还提出Distillation的方法 [5],从深度神经网络提取一些指纹来保护自己。 随着人工智能深入人们的生活,人类将越发依赖人工智能带来的高效与便捷。同时,它也成为攻击者的目标,导致应用机器学习的产品和网络服务不可依赖。GeekPwn2016硅谷分会场所揭示的是顶级安全专家对机器学习安全方面的担忧。随着一个个应用场景被轻易的攻破,尽管目前只是在语音,图像识别等场景下,我们可以清醒的认识到,当这些场景与其他服务相结合的时候,攻击成功的严重后果。人工智能作为未来智能自动化服务不可缺少的一个重要部分,已然是安全行业与黑产攻击者抗争的新战场。 Bibliography[1] A. Kurakin, I. J. Goodfellowand S. Bengio, “Adversarial examples in the physical world,” corr,2016. [2] J. Justin, K. Andrej and F.Li, “Densecap: Fully convolutional localization networks for densecaptioning.,” arXiv preprint arXiv:1511.07571 , 2015. [3] N. Carlini, P. Mishra, T.Vaidya, Y. Zhang, M. Sherr, C. Shields, D. Wagner and W. Zhou, “HiddenVoice Commands,” in USENIX Security 16, Austin, 2016. [4] P. Lamere, P. Kwork, W.Walker, E. Gouvea, R. Singh, B. Raj and P. Wolf, “Design of the CMUSphinx-4 Decoder,” in Eighth European Conference on Speech Communicationand Technology, 2003. [5] N. Papernot, P. McDaniel, X.Wu, S. Jha and A. Swami, ” Distillation as a Defense to AdversarialPerturbations against Deep Neural Networks Authors:”. [6]Y. Liu, X. Chen, C. Liu andD. Song, “Delving into transferable adversarial examples and black-boxattacks,” in ARXIV. * 本文转载自“百度安全实验室”微信公众账号,作者曹跃、仲震宇、韦韬 ,原文地址 |